Speak, LLaMA, Speak
A Study of Speech Tokenization and Modeling Approaches
Parth Sarthi
CS224S: Spoken Language Processing
Stanford University
Abstract.
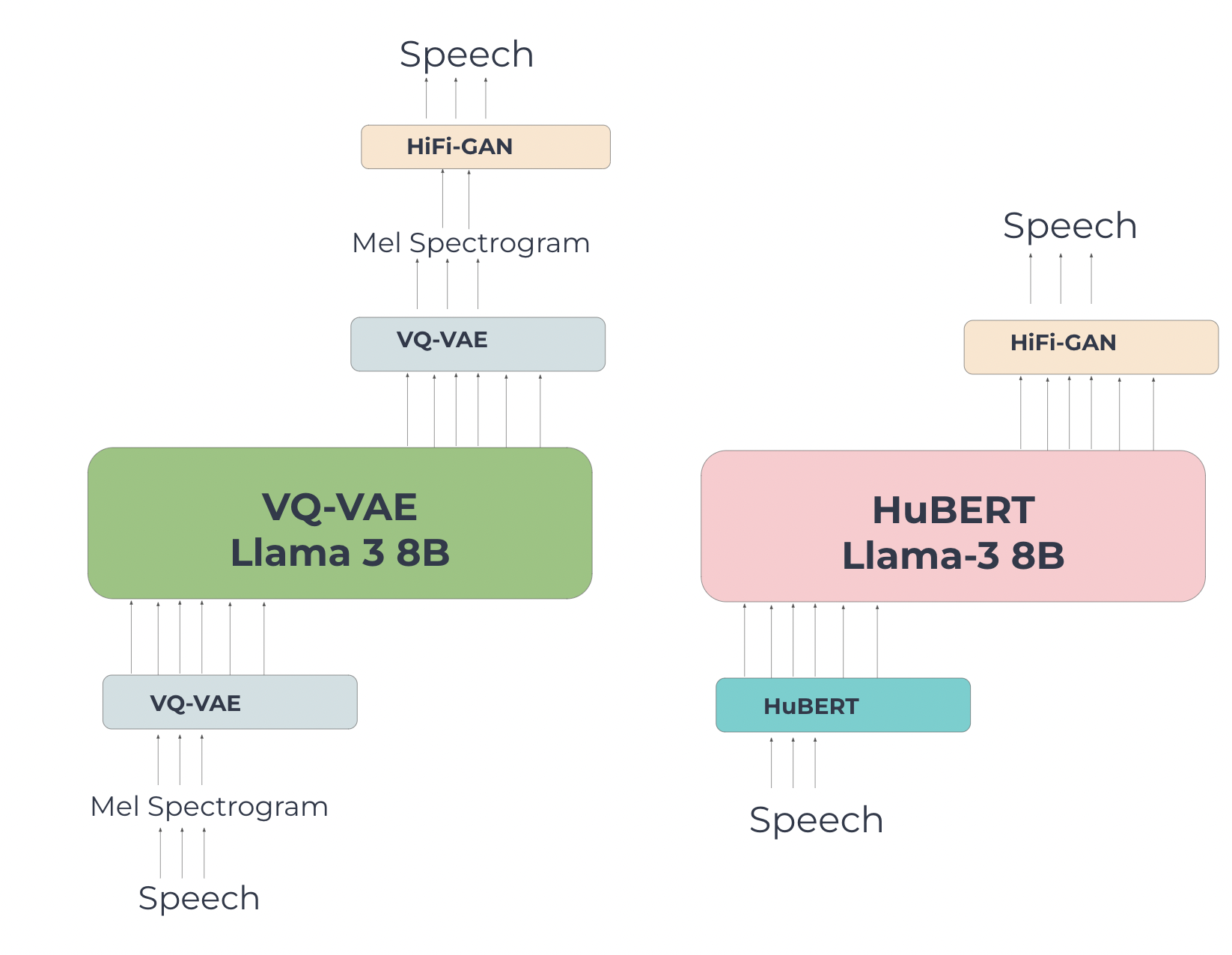
In this paper, we present SpeakLlama, an extension of the Llama 3 language model to understand and output speech, comparing the performance of two tokenization methods: HuBERT and VQ-VAE. We train Llama 3 8B on Automatic Speech Recognition (ASR), Text-to-Speech (TTS), and speech continuation tasks using both tokenizations. Our experiments reveal that HuBERT outperforms VQ-VAE in the transformer setting, with Llama 3 8B achieving a Word Error Rate (WER) of 24.7 in ASR, surpassing the baseline HuBERT ASR model's WER of 36.6. As a further extension, we train diffusion models conditioned on the same tokenizations and find that VQ-VAE achieves better loss values and reconstruction quality in the diffusion setting. Our findings suggest that the choice of tokenization method depends on the modeling architecture employed.
Overview
TTS Samples
| Text | HuBERT + Llama 3 (8B) | VQVAE + Llama 3 (8B) |
|---|---|---|
| And I also think about too, like if we attach it to like other things, like, uh, | ||
| For the past ten years, Conseil had gone with me wherever science beckoned. | ||
| There were only four stationers of any consequences in the town, and at each Holmes produced his pencil chips, and bid high for a duplicate. |